This post is republished from the Chronosphere blog. With Chronosphere’s acquisition of Calyptia in 2024, Chronosphere became the primary corporate sponsor of Fluent Bit. Eduardo Silva — the original creator of Fluent Bit and co-founder of Calyptia — leads a team of Chronosphere engineers dedicated full-time to the project, ensuring its continuous development and improvement.
 Logs are the foundational data of any observability effort. Elasticsearch allows us to store, search, and analyze huge volumes of data quickly, making it ideal for the massive volumes of log and other telemetry data generated by modern applications. It is also one of the components of the ELK Stack (Elasticsearch, Logstash, and Kibana), a widely-used log management solution for companies.
Logs are the foundational data of any observability effort. Elasticsearch allows us to store, search, and analyze huge volumes of data quickly, making it ideal for the massive volumes of log and other telemetry data generated by modern applications. It is also one of the components of the ELK Stack (Elasticsearch, Logstash, and Kibana), a widely-used log management solution for companies.
Fluent Bit is the leading open source solution for collecting, processing, and routing large volumes of telemetry data. When used as the agent for sending logs to Elasticsearch you have a highly performative telemetry pipeline.
Here we will show you how to send logs to Elasticsearch using Fluent Bit.
Before we get started
This tutorial assumes that you already have Fluent Bit installed and running on your source. It also assumes that you have Elasticsearch.
For this tutorial, we will be running Fluent Bit on an EC2 instance from AWS running Amazon Linux2 and sending the logs to Elastic Cloud, Elastic’s hosted service. The configurations you use will vary slightly depending on your source and whether you are using Elastic Cloud or another version of Elasticsearch
Configure Fluent Bit
Input Configuration
Fluent Bit accepts data from a variety of sources using input plugins. The Tail
input plugin allows you to read from a text log file as though you were running
the tail -f command
Add the following to your fluent-bit.conf file.
|
|
Depending upon your source, you may need to adjust the Path parameter to point
to your logs. Name identifies which plugin Fluent Bit should load, and is not
customizable by the user. Tag is optional but can be used for routing and
filtering your data (more on that below).
Output Configuration
As with inputs, Fluent Bit uses output plugins to send the gathered data to their desired destinations.
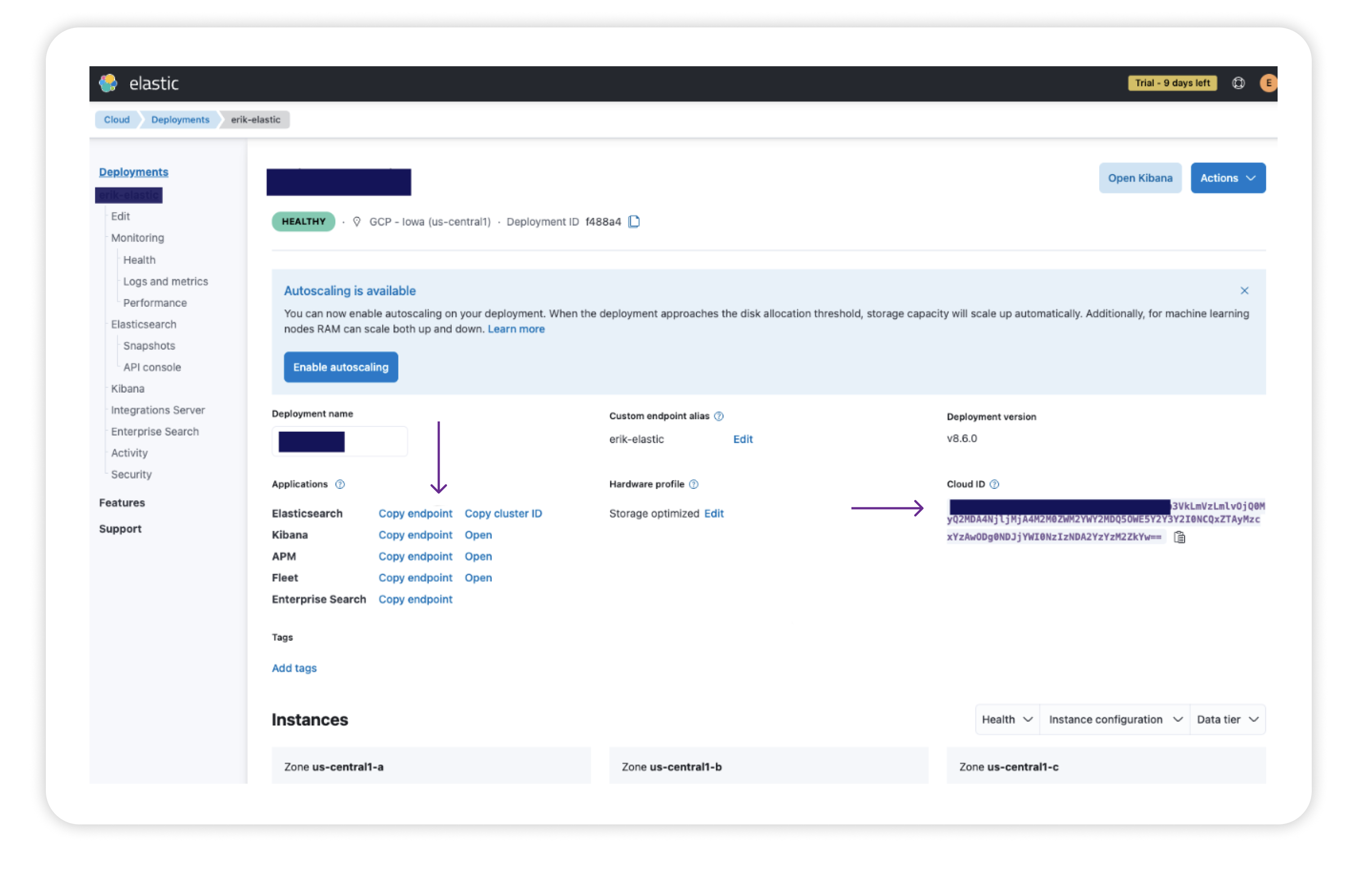
To set up your configuration you will need to gather some information from your Elasticsearch deployment:
- The endpoint — see the image below for how to locate from the console
- The Cloud ID — see the image below for how to locate from the console
- The port number — if using Elastic Cloud this will be 9243
- The authentication credentials — these will have been provided to you when you created your Elasticsearch cluster. If you failed to make note of them you can reset the password.
Once you have gathered the required information, add the following to your fluent-bit.conf file below the Input section.
|
|
The host is your Elasticsearch endpoint. Cloud_Auth corresponds to your
authentication credentials and must be presented as user:password.
The Match * parameter indicates that all of the data gathered by Fluent Bit
will be forwarded to Elasticsearch. We could also match based upon a tag defined
in the input plugin. tls On ensures that the connection between Fluent Bit and
the Elasticsearch cluster is secure. By default, the Port is configured to
9200, so we need to change that to 9243, which is the port used by Elastic Cloud
We have also defined a secondary output that sends all the data to stdout.
This is not required for the Elasticsearch configuration but can be
incredibly helpful if we need to debug our configuration.
Start Sending Your Logs!
Once you have saved the changes to your fluent-bit.conf file, you’ll need to restart Fluent Bit to allow the new configuration to take effect:
|
|
Check to make sure Fluent Bit restarted correctly.
|
|
Again, these commands may differ depending on your system.
Your logs should now be flowing into Elasticsearch, and you should be able to search your data.
Additional Configuration Settings
We’ve just seen a basic configuration for getting log data from an AWS EC2 instance into Elasticsearch in Elastic Cloud. The Fluent Bit Elasticsearch output plugin supports many additional parameters that enable you to fine-tune your Fluent Bit to Elasticsearch pipeline, including options for using Amazon Open Search. Check out the Fluent Bit documentation for more.
Fluent Bit also allows you to process the data before sending it to their final destination. You can, for example:
- Convert unstructured data to structured data
- Add additional data that would generally be lost downstream
- Redact sensitive data
- Route data to different backends depending upon its content or tag
Routing is particularly powerful as it allows you to redirect non-essential data to cheaper storage (or even drop it entirely), potentially saving you thousands of dollars when using costly storage and analysis applications priced by consumption.
Why Use Fluent Bit?
You may be asking yourself why you should use Fluent Bit rather than Elastic Agent. It’s a fair question.
Fluent Bit is vendor-neutral. Fluent Bit doesn’t care what backend you are using. It can send data to all of the major backends, such as Elasticsearch, Splunk, Datadog, and more. This helps you to avoid costly vendor lock-in. Transitioning to a new backend is a simple configuration change—no new vendor-specific agent to install across your entire infrastructure.
Fluent Bit is lightweight. Fluent Bit was created to be a lightweight, highly performant alternative to Fluentd designed for containerized and IOT deployments. Its footprint is only ~ 450kb, but it certainly punches above its weight class when it comes to being able to process millions of records daily.
Fluent Bit is open source. Fluent Bit is a graduated Cloud Native Computing Foundation project under the Fluentd umbrella.
**Fluent Bit is trusted.**Fluent Bit has been downloaded and deployed billions of times. In fact, it is included with major Kubernetes distributions, including Google Kubernetes Engine (GKE), AWS Elastic Kubernetes Service (EKS), and Azure Kubernetes Service (AKS).
Simplify your Fluent Bit-based Pipelines with Calyptia Core
As we have seen, Fluent Bit is a powerful component of your telemetry pipeline and is relatively simple to configure manually. However, such manual configuration becomes untenable as your infrastructure scales to dozens, hundreds, or even thousands of sources.
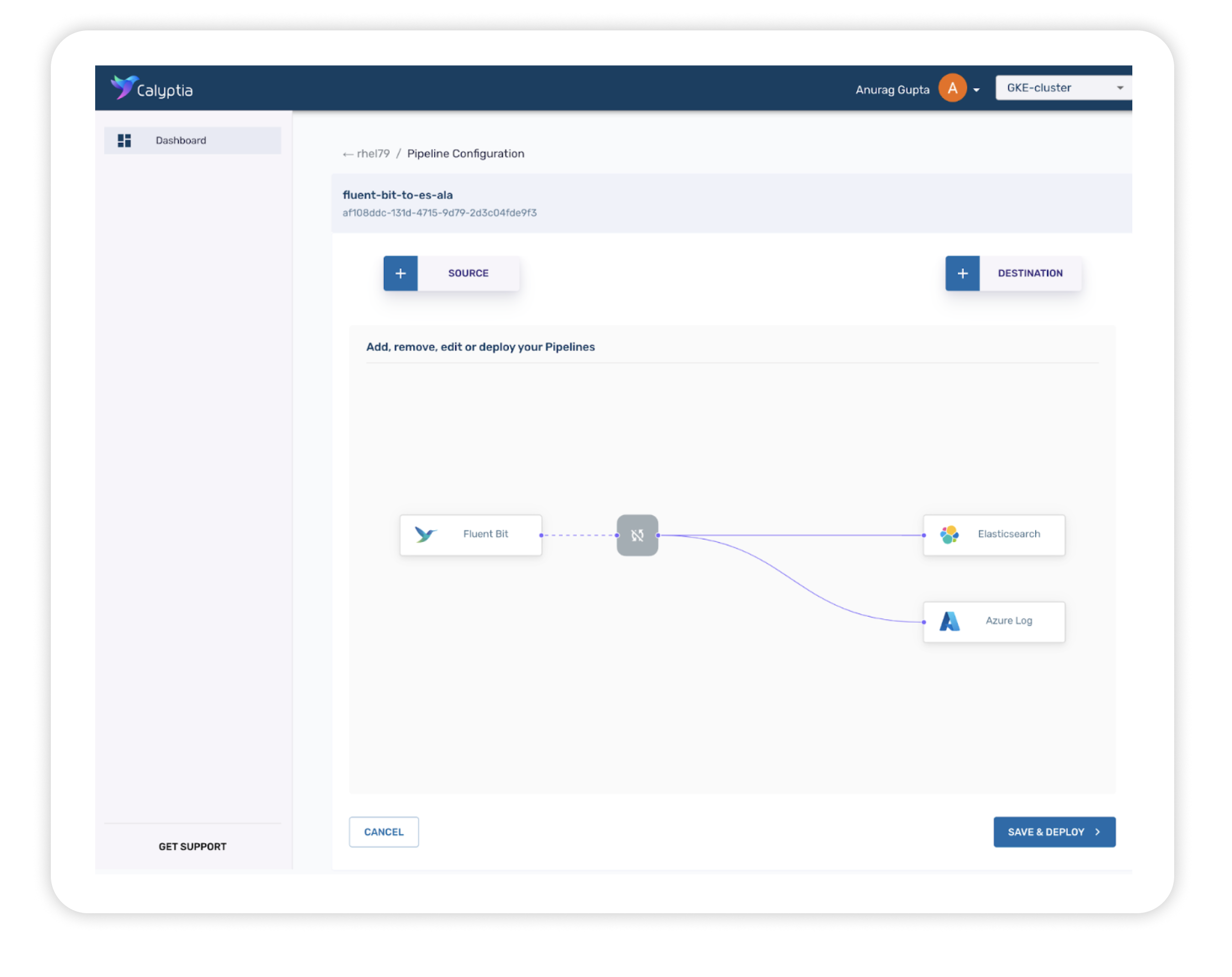 Calyptia Core allows organizations to
manage their telemetry pipelines with click-and-drag simplicity at scale. Powered by
Fluent Bit, it provides all of the benefits of the open source solution and offers a
clean and intuitive interface for managing and configuring your telemetry pipeline —
no more manual editing of config files — which can dramatically reduce the time and
resources spent on management and increase the efficiency of your Dev teams.
Calyptia Core allows organizations to
manage their telemetry pipelines with click-and-drag simplicity at scale. Powered by
Fluent Bit, it provides all of the benefits of the open source solution and offers a
clean and intuitive interface for managing and configuring your telemetry pipeline —
no more manual editing of config files — which can dramatically reduce the time and
resources spent on management and increase the efficiency of your Dev teams.
Schedule a demo to see how Calyptia Core can help you reduce costs and increase productivity.